Large language models (LLMs) have emerged as the dominant paradigm for robotic task planning using natural
language instructions. However, trained on general internet data, LLMs are not inherently aligned with the
embodiment, skill sets, and limitations of real-world robotic systems. Inspired by the emerging paradigm
of verbal reinforcement learning—where LLM agents improve through self-reflection and few-shot
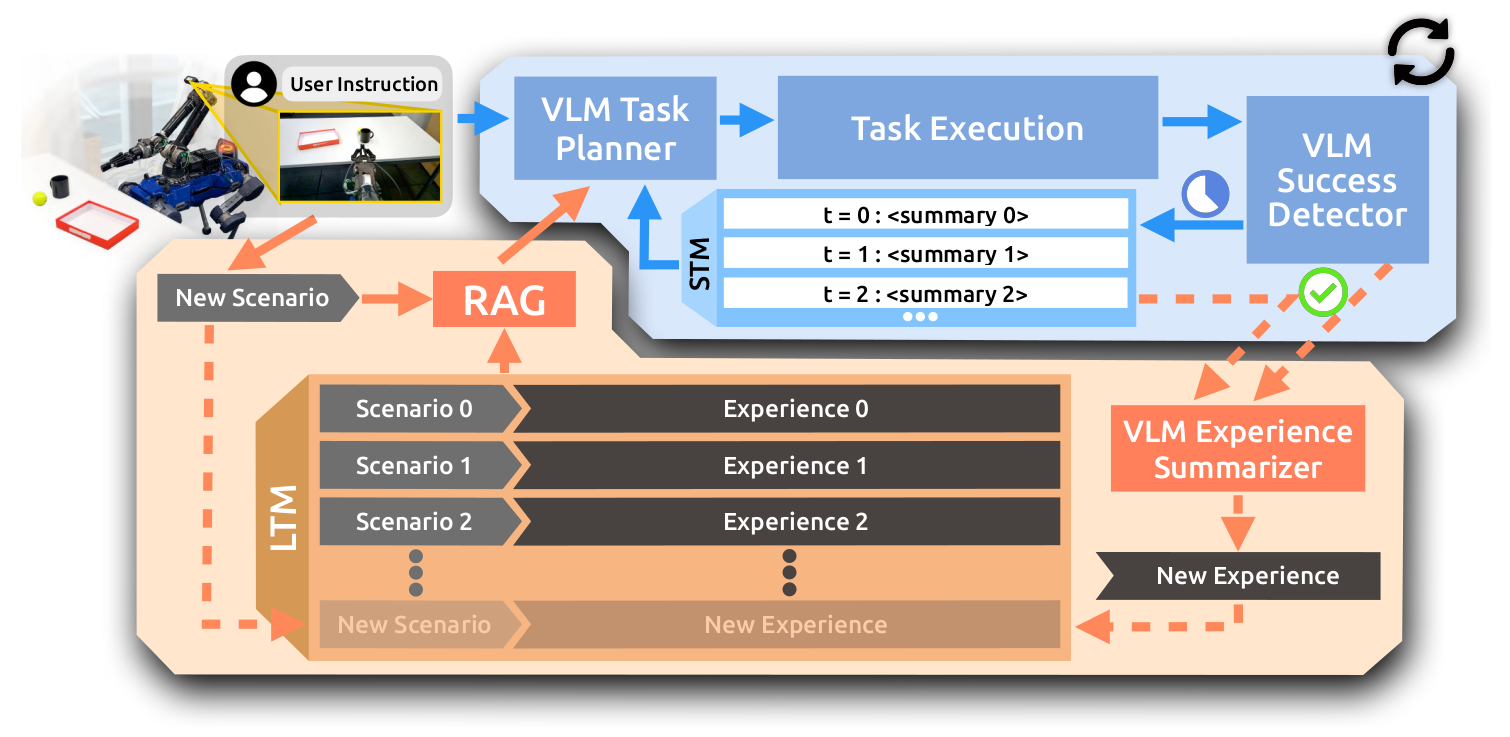
learning without parameter updates—we introduce PragmaBot, a framework that
enables robots to learn task planning through real-world experience. PragmaBot
employs a vision-language model (VLM) as the robot's “brain” and “eye”, allowing
it to visually evaluate action outcomes and self-reflect on failures. These reflections are stored in a
short-term memory (STM), enabling the robot to quickly adapt its behavior during ongoing tasks. Upon task
completion, the robot summarizes the lessons learned into its long-term memory (LTM). When facing new
tasks, it can leverage retrieval-augmented generation (RAG) to plan more grounded action sequences by
drawing on relevant past experiences and knowledge. Experiments on four challenging robotic tasks show that
STM-based self-reflection increases task success rates from 35% to 84%, with emergent intelligent object
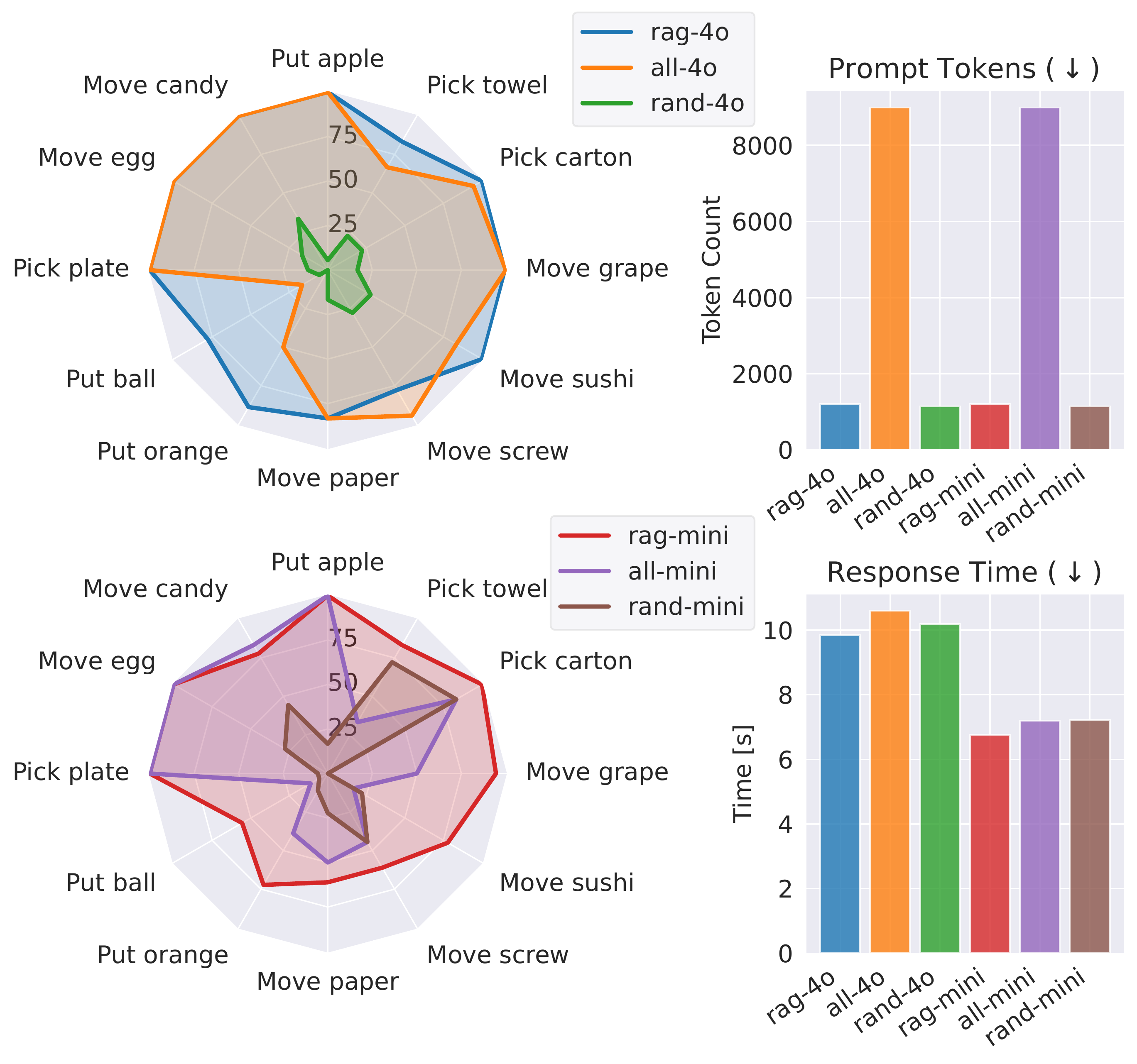
interactions. In 12 real-world scenarios (including eight previously unseen tasks), the robot effectively
learns from the LTM and improves single-trial success rates from 22% to 80%, with RAG outperforming naive
prompting. These results highlight the effectiveness and generalizability of
PragmaBot.